Millions of cells in Pathology Images: calculating cell density
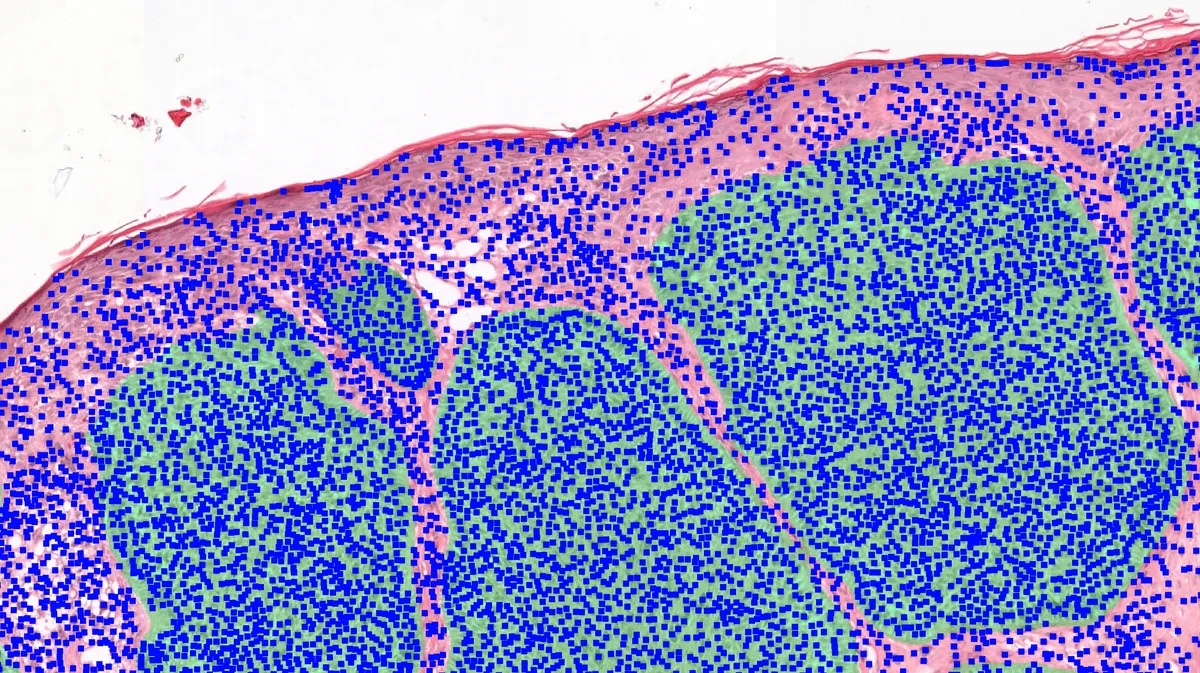
We all know that digital pathology demands efficient handling of large-scale images. However, I hadn’t anticipated that the sheer volume of cell detections would significantly impact the performance of my cell density calculations within these images. This article combines the ease of WholeSlideData, shapely, rasterio, and geopandas to achieve this in a fast and simple way.
-
WholeSlideData: Amazing useful package made by Mart van Rijthoven for handling vast pathology images and annotations with multiple backends.
-
Shapely and Rasterio: For converting image masks to polygonal representations.
-
GeoPandas: For spatial operations, making the overlap calculations efficient.
Loading the Mask
First lets load a mask that contains either tumor annotations or tumor predictions. In my case I used tumor predictions, made by one of my models.
#from wholeslidedata import WholeSlideImage
def load_mask(path, spacing):
mask_obj = WholeSlideImage(path, backend='asap')
mask = mask_obj.get_slide(spacing)
return mask.squeeze()In this method, a mask is loaded using the specific spacing. The function handles the nuances of image spacings and reads the mask at the desired resolution at once. The wholeslidedata package allows you to choose with what image backend you want to read the image. The default is OpenSlide, but in my case I use ASAP developed by Geert Litjens.
Mask to Polygon Conversion
#import shapely
#from rasterio import features
#import rasterio
def mask_to_polygons_layer(mask):
all_polygons = []
for shape, value in features.shapes(mask.astype(np.int16), mask=(mask > 0),
transform=rasterio.Affine(1.0, 0, 0, 0, 1.0, 0)):
all_polygons.append(shapely.geometry.shape(shape).buffer(0))
all_polygons = shapely.geometry.MultiPolygon(all_polygons)
return all_polygonsThis function converts a binary mask into a set of polygons using rasterio and shapely. This geometric representation is crucial for efficient spatial operations later. Okay, I admit it, its maybe hard to read and it will not win a beauty award so let me guide you through this:
Here, the function iterates through the shapes detected in the binary mask.
for shape, value in features.shapes(mask.astype(np.int16), mask=(mask > 0),
transform=rasterio.Affine(1.0, 0, 0, 0, 1.0, 0)):-
mask.astype(np.int16): The mask, which is possibly in a boolean format, is converted into an integer format suitable forfeatures.shapes(). -
mask=(mask > 0): This specifies that we are interested in the features where the mask values are greater than 0 (i.e., the foreground regions). -
transform=rasterio.Affine(1.0, 0, 0, 0, 1.0, 0): This is an identity transformation. It means that there’s no spatial transformation applied to the mask.
Then for each detected shape, the following steps happen:
all_polygons.append(shapely.geometry.shape(shape).buffer(0))-
shapely.geometry.shape(shape): This converts the detected shape into ashapelypolygon. -
.buffer(0): Thebuffer(0)trick is a common technique in GIS operations. It’s used here to fix potential topology errors in the polygons. Even though it might seem like it does nothing (since the buffer distance is 0), it can help in ensuring the created polygon is topologically valid.
Computing Cell Density
GeoPandas is an open-source Python library that makes working with geospatial data easier. While pandas is loved for data manipulation, it doesn’t have built-in capabilities to handle spatial data. GeoPandas, on the other hand, equips DataFrames with a geometry column, which can store spatial objects like points, lines, and polygons, allowing for sophisticated spatial operations. Just what I needed in this case!
Much like how pandas allows for efficient data operations due to its internal use of optimized C and Cython operations, GeoPandas spatial operations are vectorized, making spatial calculations very fast, alsoGeoPandas uses spatial indexing (via the R-tree data structure) for quick bounding box queries. When you’re trying to find overlaps between geometries (like in this case tumor polygon and cell points), spatial indexing ensures that you’re only comparing geometries that are close to one another, making overlap checks much quicker.
Lets get back to the problem and that was checking for million of cells if they where in the tumor area yes or no. GeoPandas was crucial and it took some time to figure it out, however as always, spending hours of time, the implementation was just a few lines of code. But before we start we first have to start with loading our cells.
#from wholeslidedata.annotation.wholeslideannotation import WholeSlideAnnotation
#from wholeslidedata.annotation.callbacks import ScalingAnnotationCallback
scaler = ScalingAnnotationCallback(1 / 8)
cells = WholeSlideAnnotation(cell_detections, callbacks=(scaler,), backend='asap')The cell detections are in the annotation format that ASAP uses, so we can load them using the WholeSlideAnnotation class. For .xml files WholeSlideAnnotation uses ASAP as default backend. The callbacks argument is used to specify any preprocessing steps that need to be applied to the annotations. In this case, we need to scale the annotations to the same resolution as the tumor mask. In my case the cell detections in the .xml file are coordinates in the highest resolution, which is 0.25μm/pix. However, the tumor mask is at 2μm/pix. Therefore, we need to scale the coordinates by a factor of 8.
Now with our cell detections loaded we can breakdown the cell density calculation.
#import geopandas as gpd
def cell_density(tumor_poly, cells, spacing):
cell_points = [cell._geometry for cell in cells]
a = gpd.GeoDataFrame(cell_points).set_geometry(0)
b = gpd.GeoDataFrame([tumor_poly]).set_geometry(0)
check = gpd.tools.sjoin(a, b, how='left')
counts = sum(check['index_right'].notna())
return counts / (tumor_poly.area * spacing * 10 ** -6)Here, the function converts tumor polygons and cell annotations into GeoDataFrames. The sjoin operation checks for overlaps between the two geometries. Without GeoPandas, you’d potentially be comparing every cell point with every part of the tumor polygon, a massive computational task, especially for high-resolution images. However, with spatial indexing, only cells that have a chance to overlap with the tumor are compared, drastically reducing the number of computations. Also note the set_geometry which was needed to designate a particular column as the ‘geometry’ column. This column then becomes responsible for holding the spatial data (like points, lines, or polygons) that can be used in spatial operations. I called it 0 due to convenience and make sure to use the same name so sjoin knows which geometries to compare.
check = gpd.tools.sjoin(a, b, how='left')Left here means if a point from a lies within a polygon b, the resultant check DataFrame will have that point’s data combined with the data from the polygon it lies within.
If a point from a doesn’t lie within any polygon in b, that point will still appear in the check DataFrame, but the columns corresponding to b will be filled with NaN values.
counts = sum(check['index_right'].notna())Therefore, when calculating the sum of cells that are not NaN, we get the number of cells that are within the tumor polygon. We get this data by selecting column ‘index_right’ that contains the answers for each point.
return counts/(tumor_poly.area * spacing * 10 ** -6)The purpose of the last line is to calculate and return the density of the points that are contained within the tumor polygon, in units of cells per square millimeter. Therefore we multiply with 10 ** -6 to convert the pixel spacing that has square micrometers (μm²) to square millimeters (mm²), so we end up with the metric cells/mm² tumor.
Everything put together
Want to see the full code? Check out this repository where I have put together an example notebook and normal python script and also included some example data.
pathology-cell-densityView on GitHub →A demonstration script for analyzing cell density in whole slide images (WSIs).